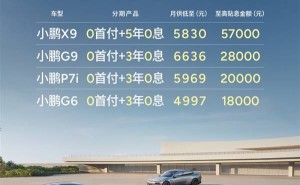
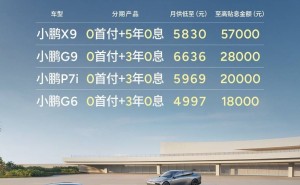
近日,Daya Guo在社交媒体平台上兴奋地分享了他的最新见闻:在春节期间,他亲眼目睹了R1-Zero模型性能曲线的不断攀升,这让他深刻感受到了强化学习(RL)技术的巨大潜力。
在大年初四这个特殊的日子里,Daya Guo不仅沉浸在节日的喜悦中,还积极回应了网友们关于DeepSeek R1模型及公司未来计划的诸多提问。他透露,尽管R1只是他们研究项目的起点,但团队内部的研发工作却从未停歇,即便是在春节期间,研究人员也依然坚守岗位,致力于推动研究成果的不断突破。
Daya Guo进一步表示,他们正在积极探索将R1模型应用于形式化证明环境的可能性,并期望能够尽快向学术界和社区发布性能更为卓越的模型版本。他坦言,团队在这一领域已经取得了显著的进展,并对未来的研究充满了期待。
Daya Guo还透露,他们正紧锣密鼓地筹备着更重磅的模型发布计划,这无疑将为相关领域的研究注入新的活力。他的这番言论,无疑让广大网友和研究者对DeepSeek的未来充满了无限的遐想与期待。