1月28日凌晨,阿里云通义千问开源全新的视觉模型Qwen2.5-VL,推出3B、7B和72B三个尺寸版本。其中,旗舰版Qwen2.5-VL-72B在13项权威评测中夺得视觉理解冠军,全面超越GPT-4o与Claude3.5。新的Qwen2.5-VL能够更准确地解析图像内容,突破性地支持超1小时的视频理解,无需微调就可变身为一个能操控手机和电脑的AI视觉智能体(Visual Agents),实现给指定朋友送祝福、电脑修图、手机订票等多步骤复杂操作。
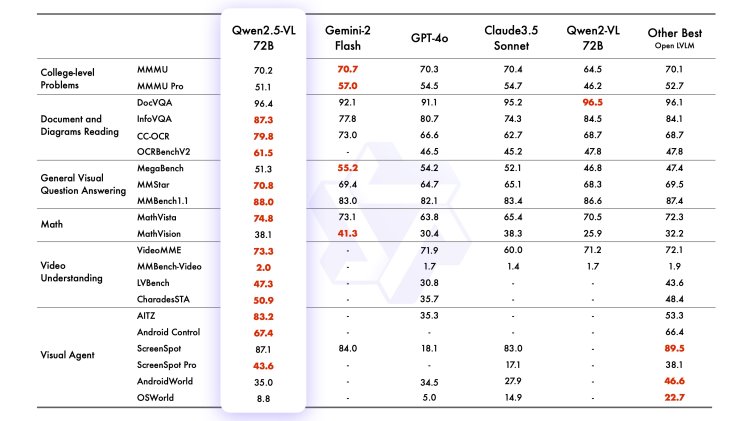
通义团队此前曾开源Qwen-VL及Qwen2-VL两代模型,支持开发者在手机、汽车、教育、金融、天文等不同场景进行AI探索,Qwen-VL系列模型全球总下载量超过3200万次,是业界最受欢迎的多模态模型。今天,Qwen-VL再度全新升级到第三代版本。根据评估,此次发布的旗舰型模型Qwen2.5-VL-72B-Instruct斩获OCRBenchV2、MMStar、MathVista等13项评测冠军,在包括大学水平的问答、数学、文档理解、视觉问答、视频理解和视觉智能体方面表现出色,全面超越GPT-4o与Claude3.5;Qwen2.5-VL-7B-Instruct 在多个任务中超越了 GPT-40-mini。
新的Qwen2.5-VL视觉知识解析能力实现了巨大飞跃:不仅能准确识别万物,还能解析图像的布局结构及其中的文本、图表、图标等复杂内容,从一张app截图中就能分析出插图和可点按钮等元素;可精准定位视觉元素,拥有强大的关键信息抽取能力,比如准确识别和定位马路上骑摩托车未戴头盔的人,或是以多种格式提取发票中的核心信息并做结构化的推理输出;OCR能力提升到全新水平,更擅长理解图表并拥有更全面的文档解析能力,在精准识别的内容同时还能完美还原文档版面和格式。


图说:Qwen2.5-VL可精准定位视觉元素,在理解图表和文档方面优势显著
Qwen2.5-VL 的视频理解能力也大幅增强,可以更好地看清动态世界。在时间处理上,新模型引入了动态帧率(FPS)训练和绝对时间编码技术,使得Qwen2.5-VL不仅能够能够准确地理解小时级别的长视频内容,还可以在视频中搜索具体事件,并对视频的不同时间段进行要点总结,从而快速、高效地帮助用户提取视频中蕴藏的关键信息。打开摄像头,你就能与Qwen2.5-VL实时对话。
视觉感知、解析及推理能力的增强,让大模型自动化完成任务、与真实世界进行复杂交互成为可能。Qwen2.5-VL甚至能够直接作为视觉智能体进行操作,而无需特定任务的微调,比如让模型直接操作电脑和手机,根据提示自动完成查询天气、订机票、下载插件等多步骤复杂任务。开发者基于Qwen2.5-VL也能快速简单开发 属于自己的AI智能体,完成更多自动化处理和分析任务,比如自动核验快递单地址与照片中的门牌号是否对应,根据家庭摄像头判断猫咪状况进行自动喂食,自动进行火灾报警等。
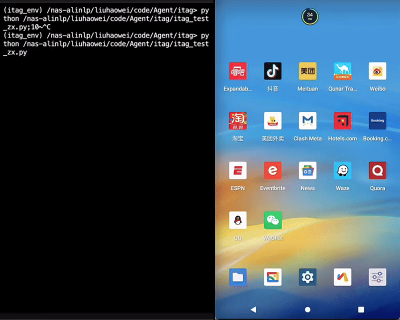
动图:Qwen2.5-VL手机端AI Agent 演示:帮我给我的QQ好友张三,发送一条新春祝福
在模型技术方面,与Qwen2-VL相比,Qwen2.5-VL增强了模型对时间和空间尺度的感知能力,并进一步简化了网络结构以提高模型效率。Qwen2.5-VL创新地利用丰富的检测框、点等坐标,让模型直接感知和学习图片在空间展示上的尺寸大小;同时,在时间维度也引入了动态FPS训练和绝对时间编码,进而拥有通过定位来捕捉事件的全新能力。而在重要的视觉编码器设计中,通义团队从头开始训练了原生动态分辨率的ViT,并采用RMSNorm和SwiGLU的结构使得ViT和LLM保持一致,让Qwen2.5-VL拥有更简洁高效的视觉编解码能力。
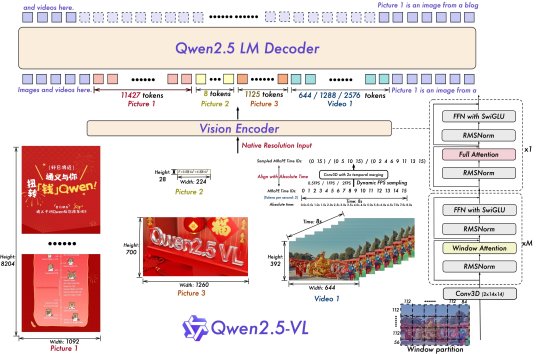
图说:Qwen2.5-VL模型结构图
目前,不同尺寸及量化版本的Qwen2.5-VL模型已在魔搭社区、HuggingFace等平台开源,开发者也可以在Qwen Chat上直接体验最新模型。
附链接:
QwenChat:https://chat.qwenlm.ai/
魔搭社区:https://www.modelscope.cn/collections/Qwen25-VL-58fbb5d31f1d47
HuggingFace:https://huggingface.co/collections/Qwen/qwen25-vl-6795ffac22b334a837c0f9a5
(完)














