2022年Intel接连发力,在6月份率先推出了旗下首款高性能桌面级GPU A380,虽然定位入门级,却也初具规模。
而在同年10月再次推出了中高性能的A750/A770桌面级GPU,本次的两款显卡一跃达到了市场主流产品的水准,虽然尚未达到旗舰级发烧性能,但其潜力可见一斑。
下面则为大家简单解析一下Intel的Xe HPG微架构,到底有何玄妙之处。
Xe HPG微架构浅析
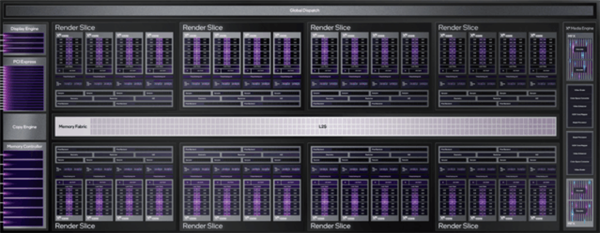
本代Intel 3款显卡采用了Xe HPG微架构设计,最初发布的入门级A380显卡包含8个Xe内核(Xe Core),即两个渲染切片(Rendering Slice),下面我们从最小的Xe Core逐步为大家讲解。

Xe Core
每个Xe Core包含16个256位宽的(XVE)矢量引擎,它主要负责传统图像处理计算的任务,且提供大部分运算。
同时由于AI算法核心几乎完全围绕着一系列大型矩阵算法和累加算法,所以每个Xe Core还包含16个1024位宽的矩阵引擎(XMX),主要为加速AI运算而生。
为了满足矩阵、矢量和光线追踪单元的高带宽需求,每个Xe Core中还构建了一个192KB的大型本地内存。它可以根据每个工作负载的需要在L1缓存和共享本地内存(SLM) 之间动态分配。

Render slice
综上所述,每4个微小的Xe Core,将构成一个Render slice(渲染切片)。除此之外,每个Render slice还集成了几何处理、光栅化、纹理采样、像素处理和光线跟踪等主流图形技术。
新的光线追踪单元架构可为DirectX Raytracing和Vulkan RT提供全面支持,通过加速光线遍历、光线盒交叉点和光线基元交叉点实现逼真的闪电和视觉保真度。
Xe HPG
Xe HPG架构最大的特点就是出色的灵活性,Intel可通过叠加渲染切片的方法来构建不同核心,目前最少为2个(8 Xe Core),最大可以做到8个(32 Xe Core),A380为两个,而A770则为8个Render slice。
通过此方法,可实现GPU配置从低功耗解决方案扩展到旗舰级的游戏引擎。每个Render slice通过大型L2缓存的高带宽内存交换矩阵,能够灵活地扩展到强大的多切片配置,并连接到独立的GPU基础架构。
具有连接每个切片的大型二级缓存的高带宽内存交换矩阵能够灵活地扩展到强大的多切片配置,并连接到独立的GPU基础架构。
Intel Xe HPG微架构 其他特性
XeSS 超级采样
针对游戏帧数优化方面,目前NVIDIA拥有DLSS、NIS技术,AMD拥有FSR、RSR技术,这几种技术旨在降低渲染分辨率,输出高帧率画面,但原理有所不同。
而Intel的XeSS超级采样技术,同样在未发布时就引起了玩家的高度关注。
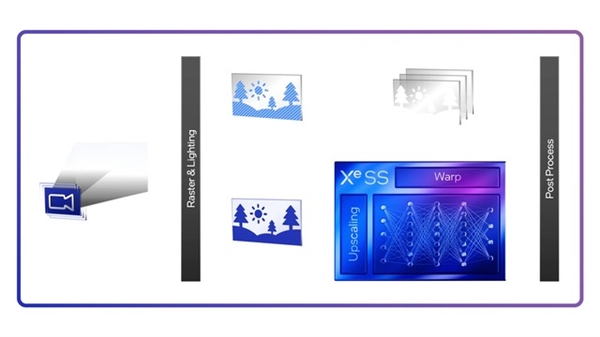
它是由机器学习通过相邻像素以及运动补偿先前帧重建子像素细节,可以帮助合成非常接近于原生超高分辨率渲染质量的图像。
整体算法采用了人工智能算法和硬件加速,以较低分辨率渲染所要求的性能水平,提高输出分辨率,提供超高清视觉效果,性能可提高2倍。
根据官方的描述,XeSS采用了与DLSS相似的时间算法,它类似于用相机拍摄长曝光,捕捉的时间越长,收集到的细节也就越多。

在多个不同帧之间,AI会通过运动矢量来跟踪对象并分析数据,并决定如何将它们结合在一起。XeSS会通过中间帧和前后帧,收集超高像素后,再经由AI网络处理,输出相对较小且清晰的画面。
和时间算法相比,NIS、FSR、RSR这类空间缩放算法则只能取一个像素点附近的低分辨率图像进行采样,然后缩放锐化。但锐化并不能从低分辨率图像中创建额外的细节,只能提高低分辨率信息中已经存在的细节对比度。

令人惊喜的是,XeSS是采用开放标准实现的。换句话说,在游戏厂商的支持下,它可以适配多家GPU广泛使用。当然,XeSS算法在Xe GPU的DP4a和XMX硬件功能下,会呈现更好的性能效果。
Deep link
Deep link可充分利用Intel CPU和GPU协同工作,完成如视频转码,直播推流等任务,编解码优势显著。Deep link并不是某种具象技术,而是多项技术的总称,下面我们来分别讲解。

Stream Assist
Stream Assist技术主要针对游戏主播,或者有直播需求的用户。在开启直播时,Stream Assist可将直播负载分载到系统中的辅助引擎,从而优化游戏性能。性能更强的独显则依旧负责游戏运算,以获得最高的帧率和协同工作效率。
另外集显负责直播的同时,还负责捕获任务(如虚拟绿屏、自动构图、清晰直播和自动捕捉游戏精彩时刻)。

需要注意的是,台式机如果想使用Stream Assist技术,前提是与12代酷睿处理器或代次更高的处理器搭配使用,另外需要带有集成显卡的处理器,后缀带有“F”的则无法使用。
超级编码、超级计算
超级编码可以让Intel平台上并行工作的多个媒体引擎(适用于看重工作效率的选定应用程序),加速编码。从而让用户花更少的时间等待项目输出,最大限度地发挥创作动力。
而超级计算则需要用到XMX引擎,它可以利用Intel平台上的多个计算引擎和 AI 加速器(适用于看重工作效率的选定应用程序),加速内容创作。

同样,这两项技术均需要搭载12代酷睿处理器或代次更高的处理器搭配使用,另外需要带有集成显卡的处理器。
这里着重说一下超级编码,它可以使用CPU和GPU上所有可用的媒体编码引擎,某种意义上说,可以看做双显卡共同编码。
我们此前的编码工作,无论使用CPU或者GPU,都是单线程工作。而Intel超级编码则是通过OneVPL这个跨平台的开放性框架,让CPU和GPU协同工作。

当超级编码开始工作时,一组组解码后的原始帧通过特定的API函数被交给oneVPL,进而按组被分配到不同的多媒体引擎上,拷贝到相应的内存中缓存起来。
不论每一组有多少帧,相应的集显或者独显的多媒体引擎会开始按照设定的格式编码。而OneVPL会完成后续的打包工作,把编码后的帧一组组拼接成最终视频来输出。这种并行处理,编码效率比单一显卡更加显著。
高级Xe媒体引擎
高级Xe媒体引擎带有专门AI加速、宽编解码器支持,包含H.264/AVC、H.265/HEVC、VP9以及AV1。并且得益于强大的媒体引擎,它也是全球首款支持AV1硬件编码的GPU。与软件编码相比,编码速度提高了50倍。
AV1与H.265编解码谁才是未来一直广受争议,从压缩效率来讲,AV1比最为常见的H.264编解码器高出50%,比H.265高30%。换句话说,对于相同的图像质量,AV1可以比HEVC节省多达30%的文件大小。
当然,如此强大的AV1也需要更强大的硬件来解码,即便如此,它也比HEVC需要更长的时间来解码。并且HEVC已经由AMD、NVIDIA、Intel、Apple、高通等公司的GPU/CPU支持,而AV1目前的支持是有限的。
最重要的是,AV1是完全开放没有任何授权费用的编解码器。虽然目前还没有被广泛采用,但行业内用户对其前景非常认可。
目前,包括FFMPEG、Handbrake、Adobe和XSplit都已集成了对锐炫AV1的支持。
结语:
作为Intel第一代高性能独显架构,Xe HPG微架构从硬件水准来说,显然已经达到预期,目前欠缺的只是软件方面的优化。根据Intel官方说明,刚刚发布的A770已经达到了最大的8个Render Slice成为完全体,性能的提升也是有目共睹。
当然一代架构并不能说明太多问题,我们还要看后续以Xe HPG微架构为蓝本的迭代升级效果如何,不过无论怎样,在NVIDIA和AMD两强相争多年的格局下,Intel重回高性能GPU市场,无疑会在未来几年内对市场格局带来巨大冲击。
















